STUDY
[SQLD] Chapter2. 데이터 모델과 SQL 1-1 정규화 (Normalization)
체다오니
2022. 10. 17. 23:54
- 성능 향상을 위한 데이터 모델링 수행 시점
- 사전에 미리 할수록 비용 절감 가능
- 분석/설계 단계에서 하는 것이 BEST
- 성능 고려한 데이터 모델링 순서
- 정규화
- DB 용량 산정
- 트랜잭션 유형 파악
- DB 용량, 트랜잭션 유형에 따라 반정규화
- PK/FK 조정, 슈퍼타입/서브타입 조정
- 성능관점에서 데이터모델 검증
- 성능 데이터 모델링 고려사항
- 정규화
- 중복 제거를 통해 삽입/수정/삭제 성능 향상. 조회 성능을 저하시키는 건 아니다.
- 용량 산정
- 전체적인 DB의 트랜잭션 유형과 양을 분석하는 자료가 됨
- 물리적 데이터 모델링
- PK/FK 칼럼 순서 조정
- FK 인덱스 생성 수행
- 성능 향상
- 이력데이터
- 시간에 따라 반복적으로 발생
- 대량 데이터일 수 있다
- 컬럼 추가하도록 설계
- 정규화
정규화
- 정규화 (Normalization)
- 데이터 정합성 (데이터의 정확성과 일관성을 유지하고 보장)을 위해 엔터티를 작은 단위로 분리하는 과정
- 중복 제거, 무결성을 지킴
- 성능은 조회 & 삽입/수정/삭제 의 두 가지 측면 둘다 고려 해야 한다.
- 정규화 -> 삽입/수정/삭제 성능 향상 (조회 성능을 저하시키는 건 아니다)
- 반정규화 -> 조회 성능 향상 (중복 만들어서 -> 조인할 필요 x)
- 함수적 종속성에 근거한 정규화 수행 필요
- 함수의 종속성 (Dependency)는 데이터들이 어떤 기준값에 의해 종속되는 현상을 지칭
| 결정자 | 종속자 |
| 주민등록번호 | 이름, 출생지, 주소 |
(1) 제1정규형
- 모든 속성은 반드시 하나의 값만 가져야 한다.
- 유사한 속성이 반복되는 경우도 1차 정규화 대상
- 데이터 등 중복된 것이 많아보이면 1차 정규화 대상
- 중복된 게 안 보인다 -> 1차 정규화 완료 -> 2차 정규화 대상

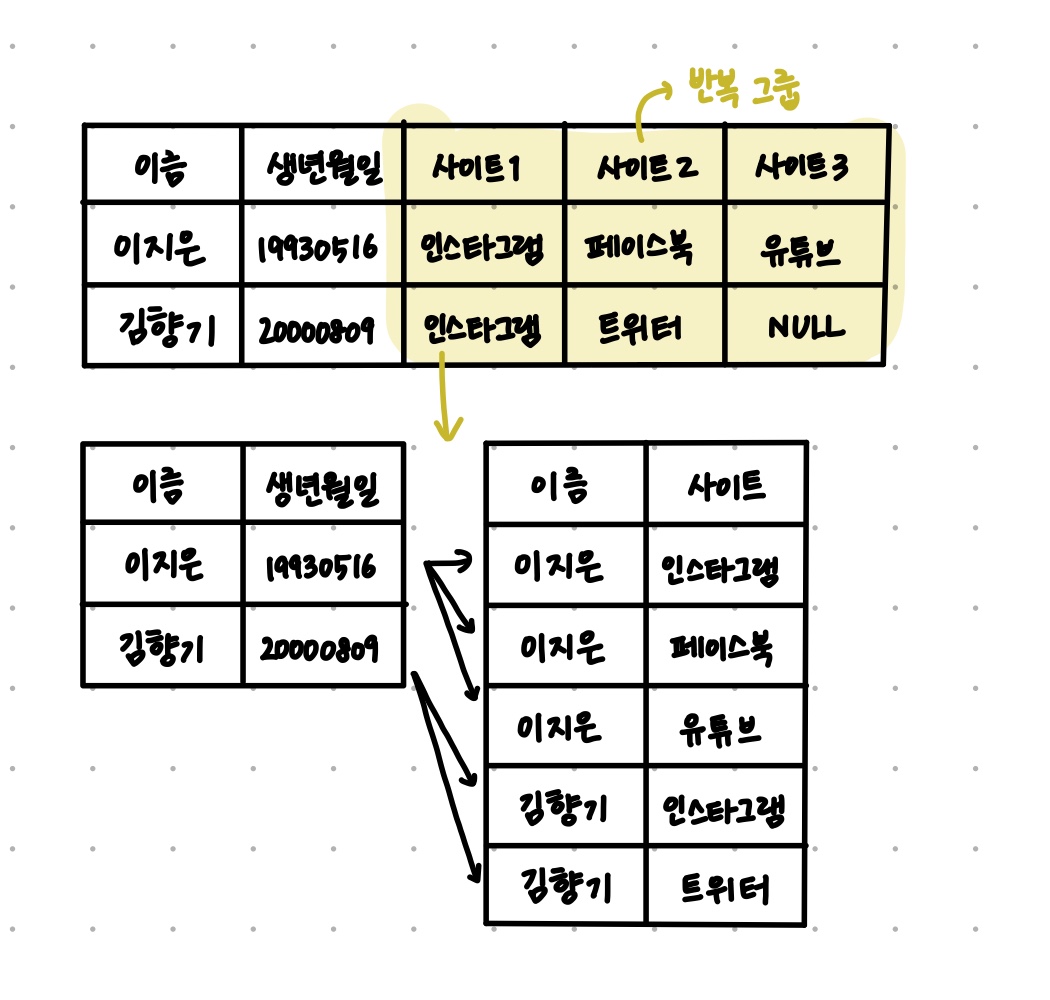
(2) 제2정규형
- 엔터티의 모든 일반속성은 반드시 모든 주식별자에 종속되어야 한다.

- 주문이 발생하지 않으면 음료 입력 불가 -> 입력 이상
- 음료명이 변경될 경우 해당되는 주문 ROW UPDATE 필요 -> 수정 이상
- 음료 삭제 시 주문까지 삭제 -> 삭제 이상
(3) 제3정규형
- 주식별자가 아닌 모든 속성 간에는 서로 종속될 수 없다.

(4) 제4정규형 - 다치 종속 제거
- 다치 종속: 하나의 속성이 다른 속성의 값 하나를 결정하는 것이 아니라 몇 개의 값 즉 값의 집합을 결정하는 속성.

- 만약 "홍길동"이 새로운 "언어" 배울 시 관계 없는 "자격증" 정보 입력 필요 -> 입력이상
- "언어" C++를 Python으로 변경 시 자격증 수만큼 반복적 수정 필요 -> 수정이상
- "자격증" 삭제 시 "언어"까지 모두 삭제 발생 -> 삭제이상
- 정규화 주의사항
- 지나친 정규화는 오히려 성능 저하를 일으킬 수 있다.
- 여러 번의 JOIN이 불가피하여 반정규화를 통해 성능 개선이 필요하다.
반응형